Surprisingly how we over the years have accepted that we need to invest a lot of time and energy to move data from ‘A’ to ‘B’ and to maintain a well performing data warehouse platform where your reports & queries respond within a reasonable amount of time (and I’m not referring to just SQL Server :-) ) But ‘Good’ isn’t good enough anymore; by entering the world of Big Data and the Internet Of Things your users expect sub-second ‘search engine alike’ response times from their in-company data platform too, even if new data hasn’t been crawled before or when data has to be read from an Hadoop cluster…
Luckily we can shift gears easily and move from a reactive- into a predictive mode; SQL Server 2012 Parallel Data Warehouse (aka PDW) is just that; the next generation data platform that performs at top speed from day one with many of the tuning optimizations as described on my blog already build in. With PDW in place you can focus on other things than Query performance tuning or waiting for data loads and exports to complete !
The secret sauce
The beauty of PDW is the simplicity of the scalability concept: just add more SQL Server Compute nodes and benefit from the seamless scale out engine: under the hood the PDW engine ‘stripes’ the data across many so called ‘data distributions’ (== 8 separate tables per compute node) a concept that makes it easy to keep up with your data growth needs and performance needs.
Also, SQL Server 2012 PDW already offers the new native updateable clustered columnstore Index (CCI) storage format. I’ve been working with the CCI for over 8 months now and I must say; it works like a charm! High data selectivity and significant higher data compression ratios for faster highly Parallelized query response timings. (Expect runtimes of just minutes instead of hours, or seconds instead of minutes) The new CCI algorithms allow you to search through data faster; whether is doesn’t matter if the data already resides In-Memory or not.
Your business analysts and end users will generate more extensive results faster.

Polybase for high-speed parallel Hadoop access
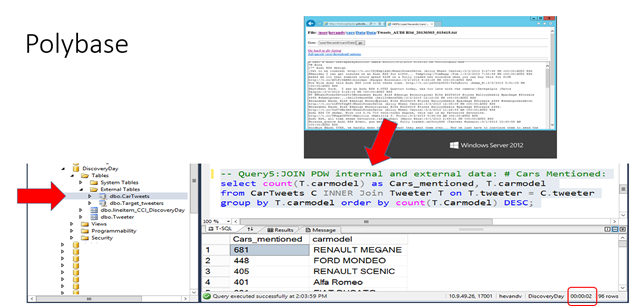
For many customers Hadoop is still just a topic on the ‘todo’ list but in case you want to get started you don’t have to be afraid of creating another data island in the lake; PDW has build in support for either writing data out or querying data stored on an Hadoop filesystem via Polybase. Polybase is fast via direct parallel HDFS access to the data nodes. From within your SQL PDW databases simply use the ‘Create External table’ command and you can both either store- or query data to /from hadoop!
Below an example of querying an hadoop cluster folder that contains many separate files with Twitter feeds; access the twitter data with a regular query without even bothering where the data comes from and receive answers within sub-seconds, as if it was stored within PDW locally !

More info on PDW Benefits (Must Reads!)
If you want to read more on SQL Server PDW, please check out : upgradetopdw.com
The PDW landing pages is simple to remember : www.microsoft.com/PDW
Or… download the whitepaper in Word format that I helped writing to explain PDW and the benefits that my customers value most when they start using SQL Server 2012 PDW, Enjoy !
download.microsoft.com/SQL Server 2012 Parallel Data Warehouse – A Breakthrough Platform


{kind=link}